De actuaris als Data Scientist? Ja, natuurlijk!
De actuaris als Data Scientist? Ja, natuurlijk!
Budget-smartphones hebben tegenwoordig meer rekenkracht dan de beroemde supercomputer Deep Blue, die in 1997 in een rechtstreeks duel toenmalig wereldkampioen schaken Garry Kasparov wist te verslaan. Tegelijkertijd groeit de hoeveelheid data wereldwijd elk jaar met bijna 50% . Deze technologische ontwikkelingen veranderen het landschap van verzekeraars. De opkomst van Big Data, in samenspel met nieuwe methodieken om deze te analyseren, zorgt ervoor dat voor het verwerken van data en het optimaal inschatten van risico’s een nieuwe set vaardigheden is vereist. Het gevolg is dat er, ook bij verzekeraars, veel vacatures openstaan met daarin termen als R, Python, Machine Learning en Big Data.
Dit is echter nog nauwelijks het geval voor posities binnen actuariaat. Juist hier kunnen Big Data en Machine Learning (een onderzoeksveld binnen Kunstmatige Intelligentie, waarbij de focus ligt op technieken waarmee computers geautomatiseerd kunnen leren) erg waardevol zijn. Met een voorbeeld uit de praktijk laten we zien dat je als actuaris zelf aan de slag kunt gaan met Machine Learning. Aan de hand van dit voorbeeld concluderen we zelfs dat de actuaris zich juist in een ideale positie bevindt om gebruik te maken van deze technologische vooruitgang.
Big Data en Machine Learning versus Conventionele data en regressies
De onderscheidende waarde van Big Data wordt vaak gekarakteriseerd door de drie V’s: ‘Volume, Velocity en Variety’ (tegenwoordig zijn er ook varianten met 7 V’s). De hoeveelheid data is groter, ververst vaker (soms in realtime) en is gevarieerder: van ouderwetse tabellen, tot de zogenoemde ongestructureerde data. Voorbeelden hiervan zijn foto’s, video’s en data van huishoudelijke apparaten. Als gevolg vereist Big Data vaak een complexere ICT-architectuur dan conventionele, gestructureerde data.
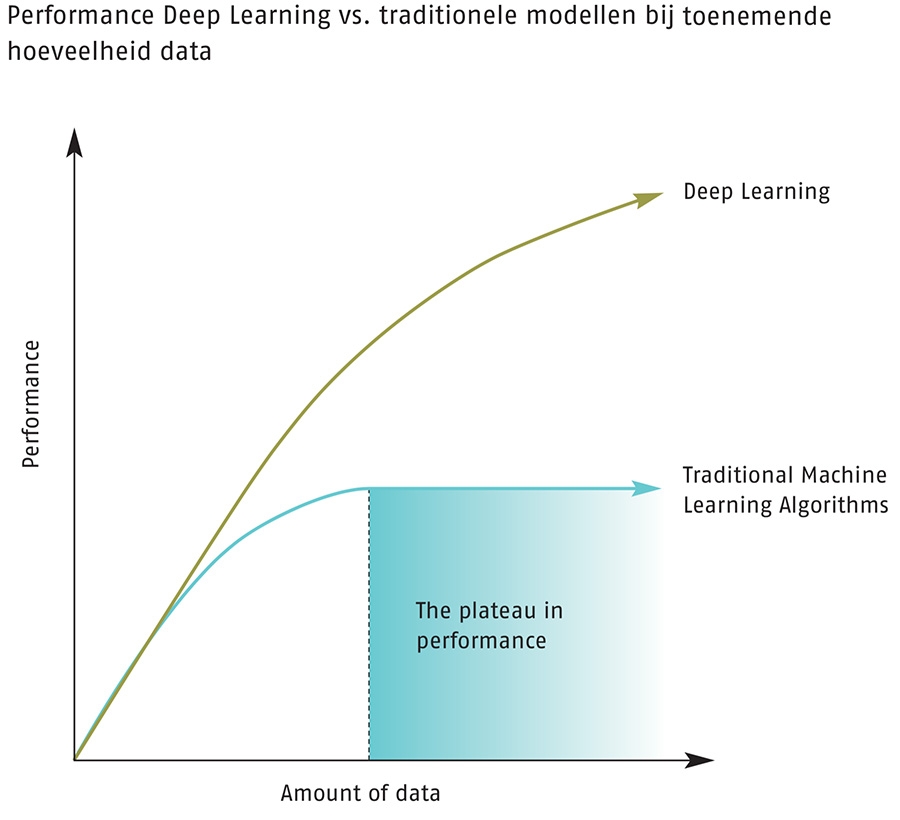
Machine Learning wordt gezien als een sub-gebied van informatica. De methoden bestaan echter al veel langer. Neurale netwerken, die de basis vormen voor de meest geavanceerde technieken van het moment, werden al voor het eerst beschreven in een artikel in 1943. Deep Learning werd in 1986 voor het eerst benoemd. Maar in die tijd presteerden eenvoudigere modellen als logistische regressies en Support Vector Machines beter. Deep Learning-modellen zijn gebaat bij veel data en hebben meer rekenkracht nodig dan traditionele modellen om goed te kunnen presteren. Echter, dat kritische punt zijn we inmiddels al lang gepasseerd, waardoor dit type algoritmes nu op vele gebieden worden toegepast. Bijvoorbeeld om in je telefoon foto’s te classificeren en om auto’s autonoom te kunnen laten rijden.
De actuaris als data scientist
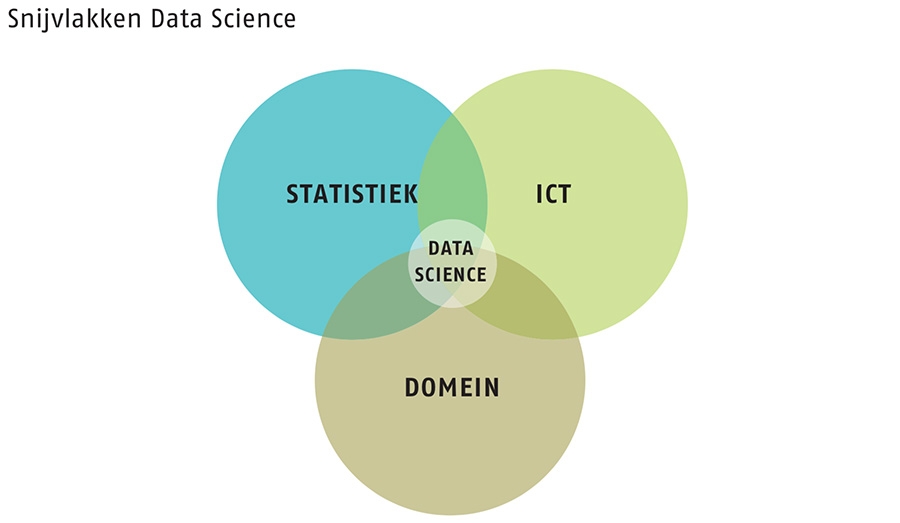
De vereiste vaardigheden voor het gebruik van Big Data en Machine Learning komen grotendeels overeen met die van de actuaris. Een Data Scientist opereert doorgaans op het snijvlak van drie gebieden: informatica, statistiek en een specifiek domein. Van deze drie is statistische kennis een basisvaardigheid voor elke actuaris, echter is kennis op het gebied van informatica niet altijd aanwezig. Ondanks dat dit een beperking kan zijn voor het werken met Big Data, hoeft dit geen probleem te zijn voor het toepassen van Machine Learning. Meer dan een basis in programmeren is niet vereist om hiermee aan de slag te kunnen gaan.
Een actuaris heeft een grote meerwaarde ten opzichte van een Machine Learning-expert vanwege zijn domeinkennis. Domeinkennis betekent in dit geval expertise omtrent bijvoorbeeld verzekeringsproducten, risicofactoren en tarifering. Bij Machine Learning wordt de beslissing om een variabele wel of niet mee te nemen namelijk grotendeels uit handen genomen. Dit heeft als voordeel dat er veel geautomatiseerd kan worden, maar brengt ook risico’s met zich mee. Gebruik van modellen zonder expertise kan dan leiden tot bijvoorbeeld ondoorzichtige tarieven, onterecht afgewezen declaraties of tarifering op basis van gereguleerde persoonskenmerken.
Ook een morele blik kan nog niet geautomatiseerd worden. Een voorbeeld hiervan is het verstrekken van een studentenlening. Als een student op basis van een model geen lening kan krijgen door bijvoorbeeld zijn ‘slechte’ postcode, zal deze geen opleiding kunnen financieren die kan zorgen voor een hoger inkomen, wat leidt tot een vicieuze cirkel. Om te laten zien hoe je als actuaris zelf aan de slag kan met Machine Learning volgt nu een voorbeeld uit de praktijk.
Betere risicogroepen met behulp van machine learning
Actuarissen maken bij tarifering vaak gebruik van Gegeneraliseerde Lineaire Modellen (GLM). Bij het schatten van een GLM wordt gebruiktgemaakt van bijvoorbeeld leeftijd, geslacht en salaris. De standaard aanpak om deze variabelen mee te nemen in het model is door het maken van staffels, waarbij de onderliggende variabelen één-dimensionaal worden verdeeld in groepen. Afhankelijk van de hoeveelheid beschikbare data kan het interval van de staffel toe of afnemen, bijvoorbeeld leeftijdsklassen van vijf of tien jaar – en eventueel kunnen kruistermen worden meegenomen. Het maken van deze staffels is vaak arbitrair: duidelijk mag zijn dat dit een versimpeling van de werkelijkheid is.
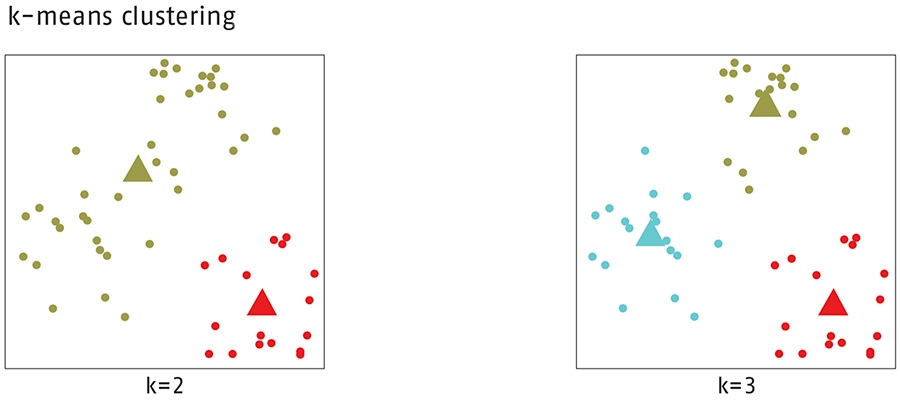
Een binnen Data Science toegepaste techniek om onderscheidende groepen te vinden is k-means clustering. Dit algoritme splitst een dataset in k niet overlappende clusters. Clustering is een voorbeeld van unsupervised learning: het ontdekken van patronen in data met minimale tussenkomst van de onderzoeker. Het doel van het k-means clustering is het vinden van homogene groepen binnen een dataset. Deze homogene groepen kunnen een natuurlijkere verdeling opleveren dan de gebruikelijke staffels.
Het k-means algoritme hebben we toegepast binnen een Logit-model voor royementen. Het algoritme heeft combinaties van leeftijd, geslacht en inkomen gevonden die met de originele staffels en interactie-effecten niet te identificeren waren. Het behoren tot één van de karakteristieke groepen die hierbij ontstonden, was een significant betere voorspeller dan het los meenemen van de variabelen waarop de clusters waren gebaseerd.
Betere resultaten door domeinkennis
Juist dit simpele algoritme laat goed zien dat er ook domeinkennis nodig is voor het toepassen van Machine Learning. We hebben clustering daarnaast ook in de praktijk gebracht bij een prijsmodel van individuele arbeidsongeschiktheidsverzekeringen. Hierbij zijn clusters opgesteld voor de beroepen van verzekerden. De resulterende groepen doen echter niet volledig recht aan de werkelijke situatie. Deze initiële indeling is besproken met een aantal domeinexperts en het bleek dat een aantal specifieke groepen niet door het algoritme werden geïdentificeerd door beperkte data voor deze groepen. De combinatie van Machine Learning en domeinkennis leidt hier tot een verfijnder en eerlijker tarief.
Conclusie
Met deze praktijkvoorbeelden laten we zien dat het zeker geen zwart-wit keuze is tussen de traditionele actuariële methodieken en nieuwe algoritmes. Eerder genoemde ontwikkelingen van rekenkracht, data en technieken zorgen er wel voor dat Big Data en Machine Learning alleen maar interessanter zullen worden binnen actuariaat. De toepassingen beperken zich niet tot clustering, maar kunnen ook gebruikt worden voor bijvoorbeeld pricing, fraudedetectie of royementsanalyse.
Dit maakt dat je als actuaris een optimale positie hebt om gebruik te maken van nieuwe data en technieken om uiteindelijk tot betere modellen en inzichten te komen. Zorg wel dat je hierbij juist gebruikmaakt van je expertise en domeinkennis en niet blind vertrouwt op modellen.
Publicaties
 Alle publicaties
Alle publicaties
Pieter Stel
De ‘black box’ uitgepakt: de mogelijke rol van Explainable Artificial Intelligence voor de verzekeringswereld
Kunstmatige intelligentie (AI) is een onmisbare trend geworden, maar deze snelle ontwikkeling brengt ook diverse uitdagingen met zich mee. Om
Kirsten de Vries
Twaalf jaar AM Flash geanalyseerd: het intermediair en volmachten worden insurtech
Het intermediair/volmacht als insurtech? Wij deden onderzoek naar de dynamiek in het intermediair en volmachtkanaal en maakten daarbij gebruik van AM:signalen van de afgelopen 12 jaar.
Kirsten de Vries
De kracht van data in de verzekeringswereld | 3 experts aan het woord
Het vertalen van data naar waardevolle inzichten zal een essentiële competentie worden binnen elke verzekeraar. Maar zijn de best practices? Lees ze in dit verslag van de round-table!-
-
Wilt u meer informatie of een afspraak maken?
Neemt u dan contact op met Daan Nijssen

Neem contact met mij op
© 2026 AAA Riskfinance. Alle rechten voorbehouden.